
Lanxiang HuI'm a PhD candidate at UCSD, fortunately advised by Prof. Hao Zhang and Prof. Tajana Šimunić Rosing, working on efficient and reliable generative AI systems. I am also a research intern at NVIDIA Cosmos Lab. Previously I was an intern at Snowflake AI research. Before joining UCSD, I have spent wonderful time working as a visiting research intern with Prof. Song Han. I completed my undergrad degree at UC Berkeley with majors in CS and Physics. I design hardware-efficient generation algorithms that turn underutilized accelerator compute into real speedups. I also build evaluation infrastructures that test whether AI systems can reason and act in interactive workloads. Some of my projects include: |
News
|
Selected Publications |
|
* denotes for equal contribution. |

|
Benchmarking Scientific Understanding and Reasoning for Video Generation using VideoScience-BenchLanxiang Hu, Abhilash Shankarampeta, Yixin Huang, Zilin Dai, Haoyang Yu, Yujie Zhao, Haoqiang Kang, Daniel Zhao, Tajana Rosing, Hao Zhang ECCV, 2026 arxiv / code / website / VideoScience-Bench is a benchmark to evaluate video generative world models not only as generators but also as reasoners, requiring their generations to demonstrate scientific understanding consistent with expected physical and chemical phenomena. |
|
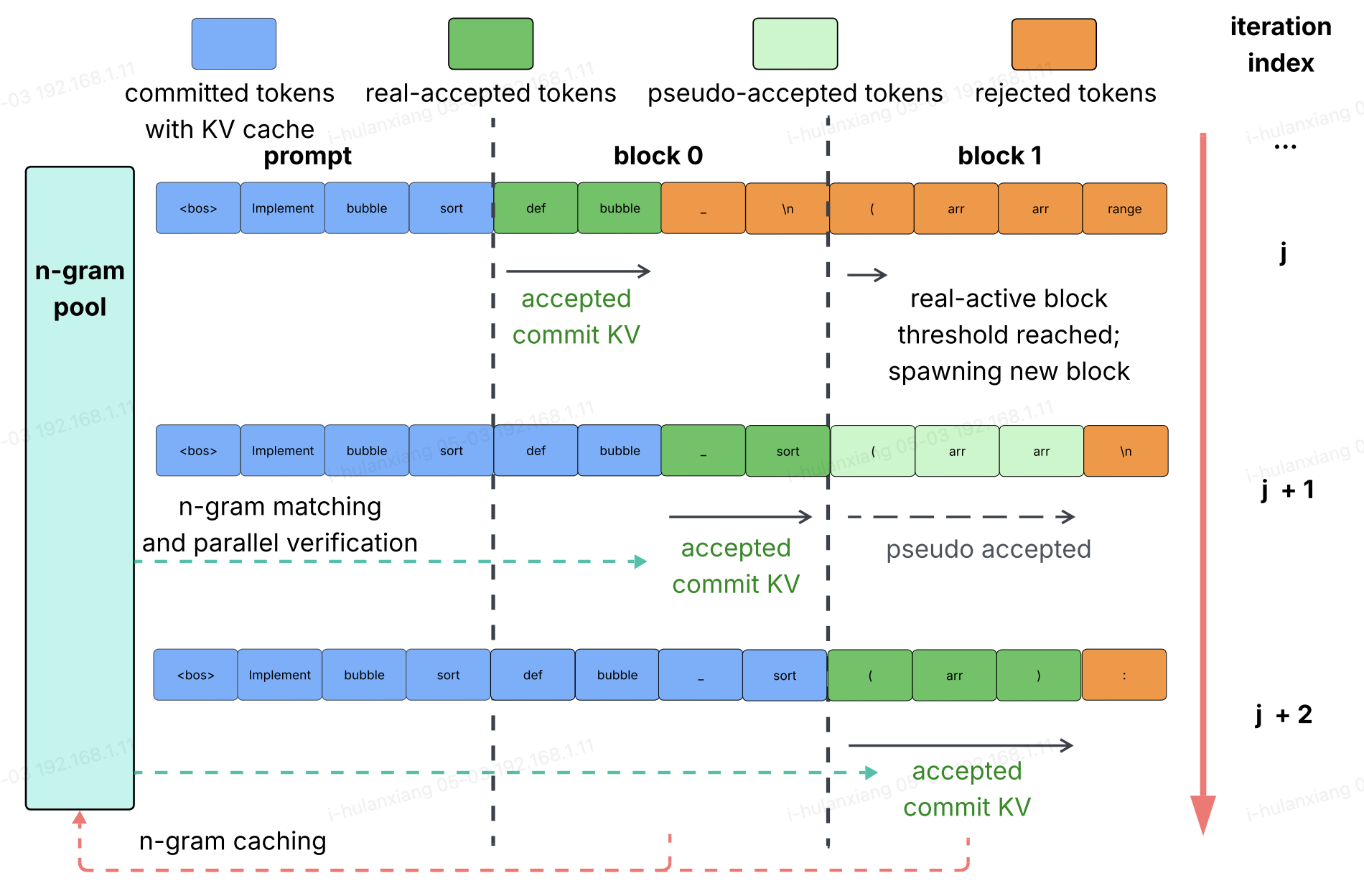
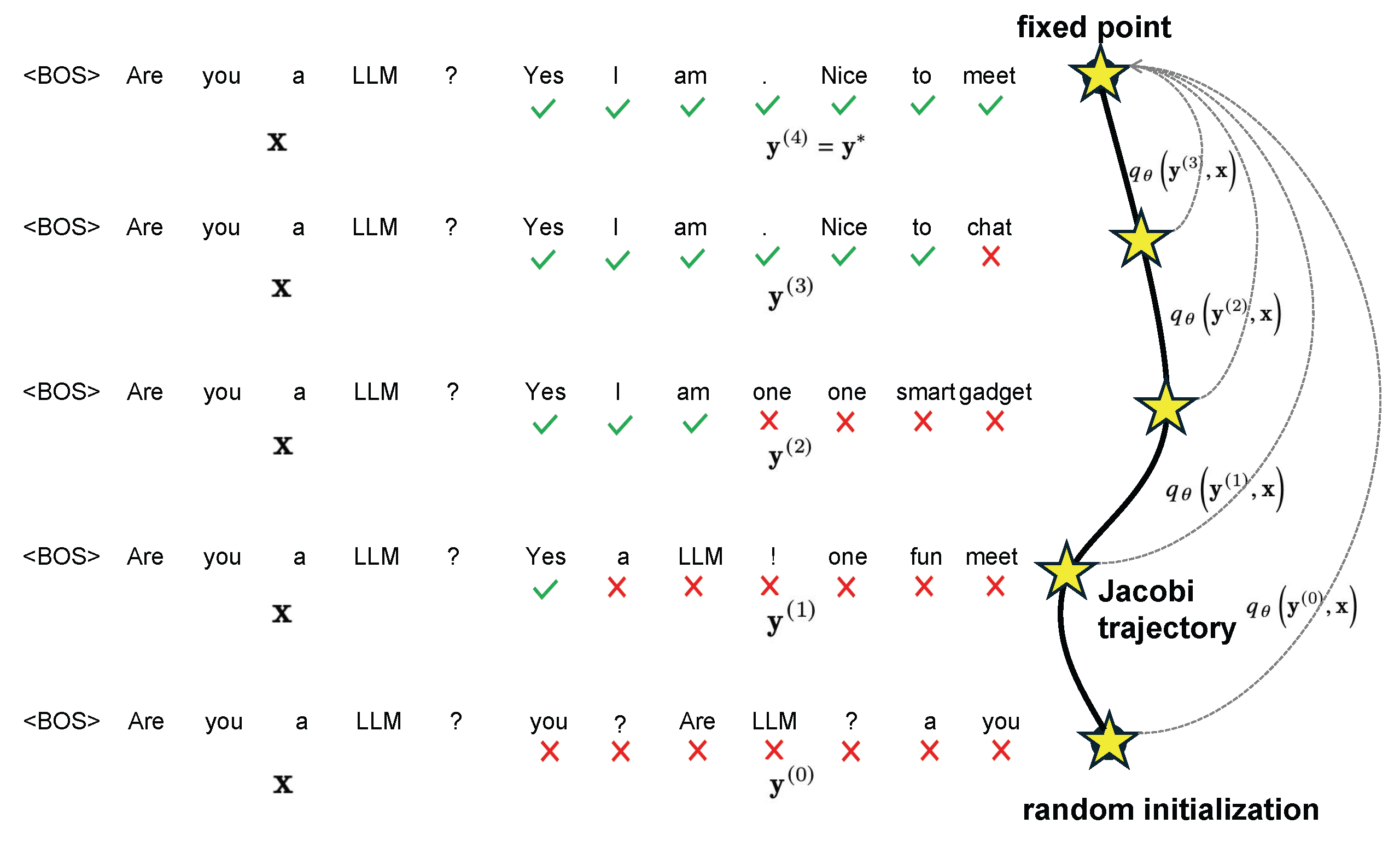
Fast and Accurate Causal Parallel Decoding using Jacobi ForcingLanxiang Hu*, Siqi Kou*, Yichao Fu, Samyam Rajbhandari, Tajana Rosing, Yuxiong He, Zhijie Deng, Hao Zhang ICML, 2026 arxiv / code / website / Jacobi Forcing trains causal parallel decoders that are able to generate high-quality drafts conditioning on noisy context. On coding and math tasks, Jacobi Forcing achieves up to 4.5x speeudp with minimal to no performance loss. |
|
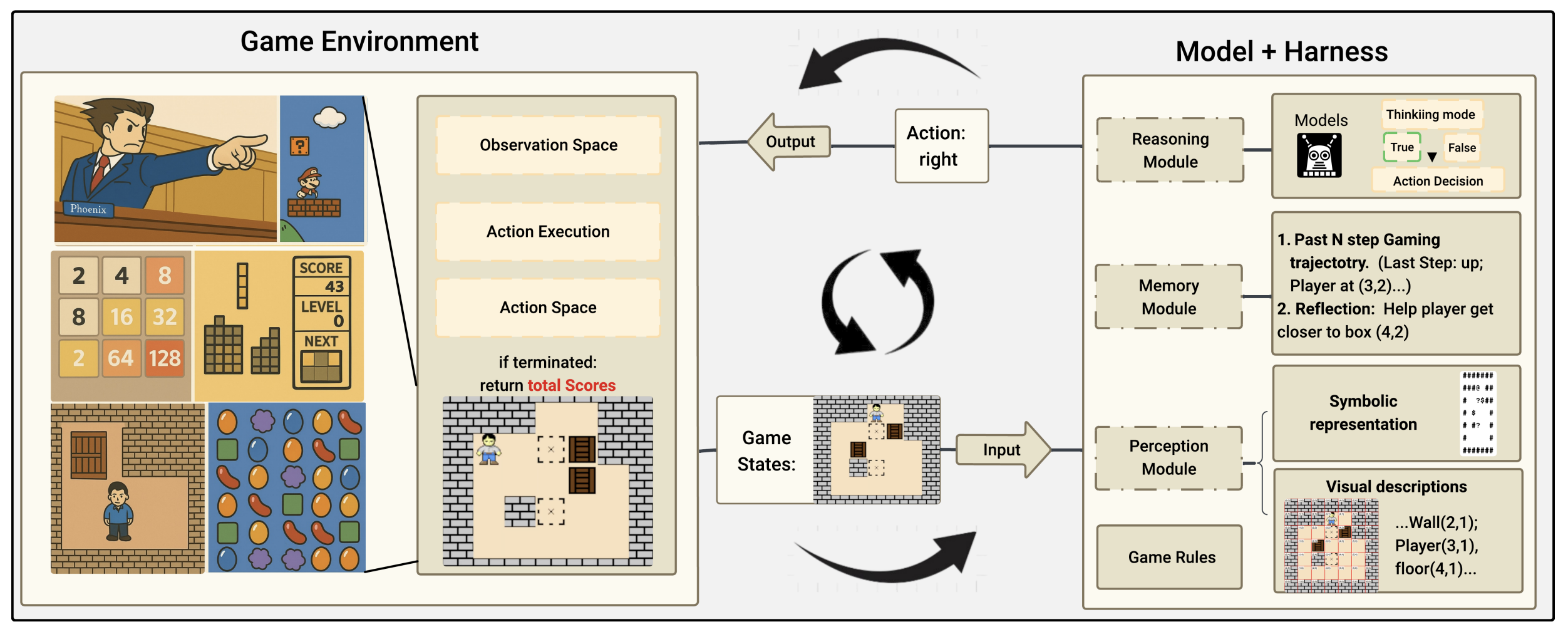
Lmgame-Bench: How Good are LLMs at Playing Games?Lanxiang Hu*, Mingjia Huo*, Yuxuan Zhang†, Haoyang Yu†, Eric P. Xing, Ion Stoica, Tajana Rosing, Haojian Jin, Hao Zhang ICLR, 2026 arxiv / code / website / We introduce lmgame-bench that evaluates latest large models with games and addresses evaluation challenges by providing scaffolds. We present quantitative analysis of the relationship between model gaming performance and results on existing benchmarks. |
|
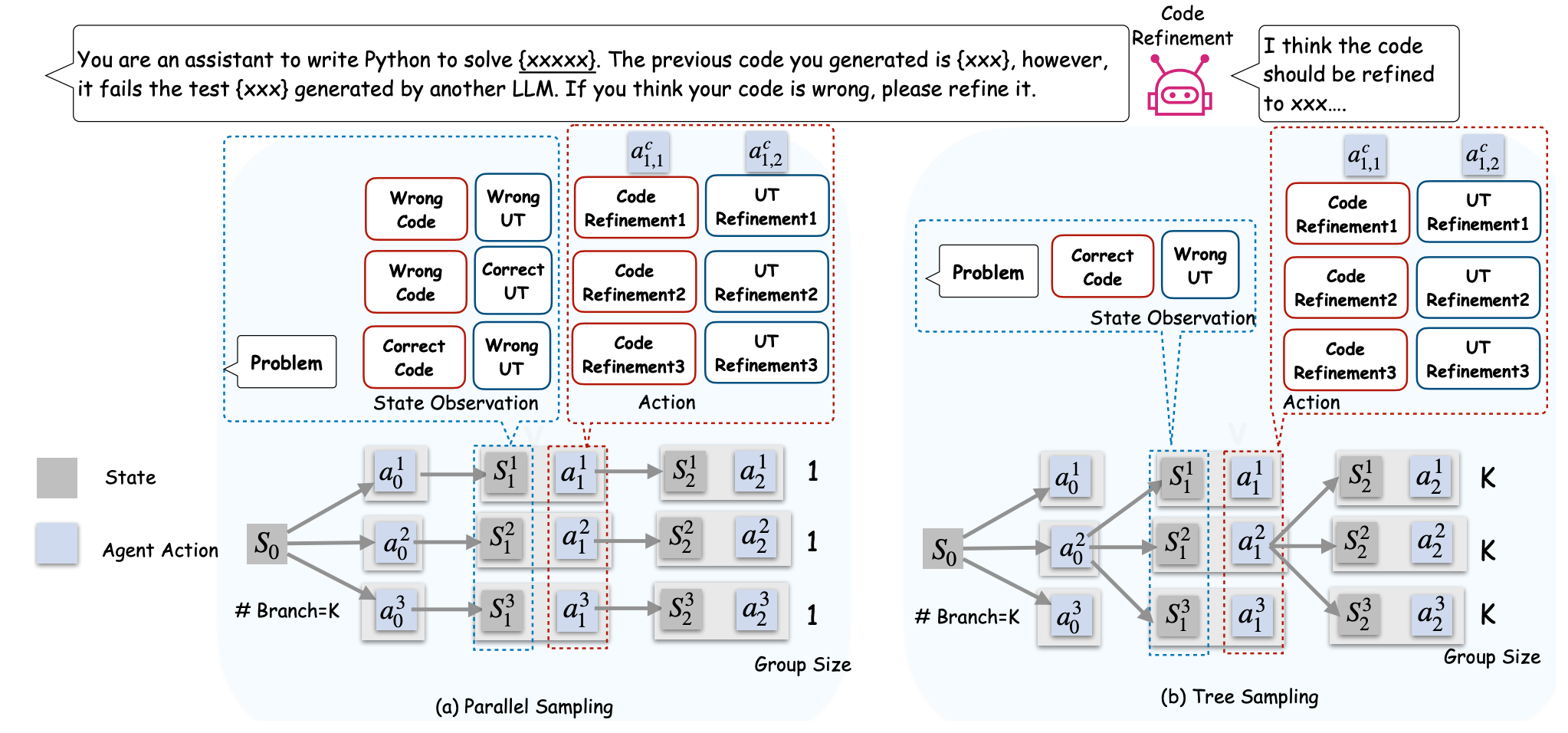
Stronger-MAS: Multi-Agent Reinforcement Learning for Collaborative LLMsYujie Zhao, Lanxiang Hu, Yang Wang, Minmin Hou, Hao Zhang, Ke Ding, Jishen Zhao ICLR, 2026 arxiv / code / website / We introduce an on-policy RL algorithm, AT-GRPO and a training system for multi-agent system training. Stronger-MAS boosts planning task accuracy from a 14.0–47.0% from single-agent RL baseline to 96.0–99.5%. It also improves reasoning performance with an average gain of 7.62% on coding and 17.93% on math. |

|
GameArena: Evaluating LLM Reasoning through Live Computer GamesLanxiang Hu*, Qiyu Li*, Anze Xie*, Nan Jiang, Ion Stoica, Haojian Jin, Hao Zhang ICLR, 2025 arxiv / code / website / We design and build a incentivized dynamic benchmarks to evaluate AI reasoning abilities extending beyond math and coding. |
|
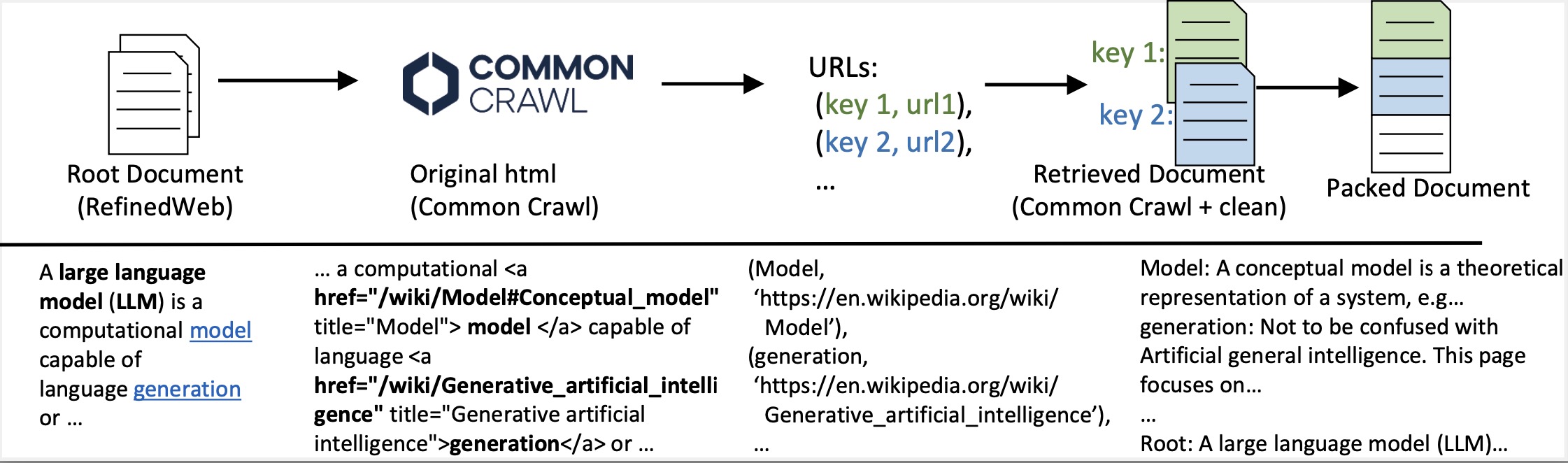
Scaling Long Context Training Data by Long-Distance ReferralsYonghao Zhuang*, Lanxiang Hu*, Longfei Yun, Souvik Kundu, Zhengzhong Liu, Eric P. Xing, Hao Zhang ICLR, 2025 arxiv / We show long distance referral is important to long context training, and design data pipeline to scale up constructing such data. |
|
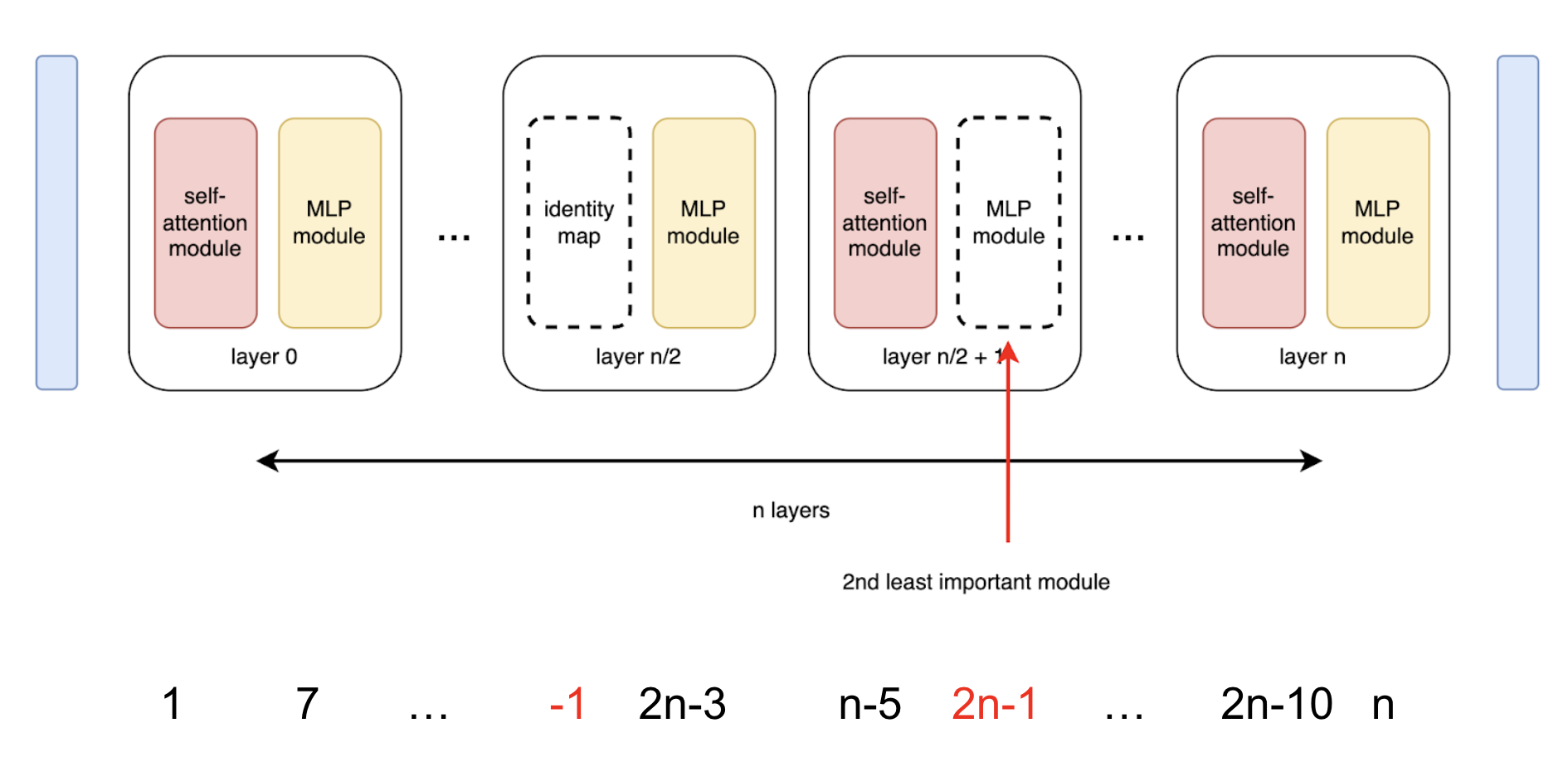
TrimLLM: Progressive Layer Dropping for Domain-Specific LLMsLanxiang Hu, Tajana Rosing, Hao Zhang ACL, 2025 arxiv / code / we introduce an algorithm to progressively prune MHA and MLP layers during domain-specific SFT to achieve up to 5.7x speedup and 60% less memory consumption in comparison with state-of-the-art model compression algorithms. |
|
CLLMs: Consistency Large Language ModelsSiqi Kou*, Lanxiang Hu*, Zhezhi He, Zhijie Deng, Hao Zhang ICML, 2024 arxiv / code / website / We show LLMs can be trained to operate LLMs as highly efficient parallel decoders with 2.4x to 3.4x speedup across a variety of benchmarks. |
|
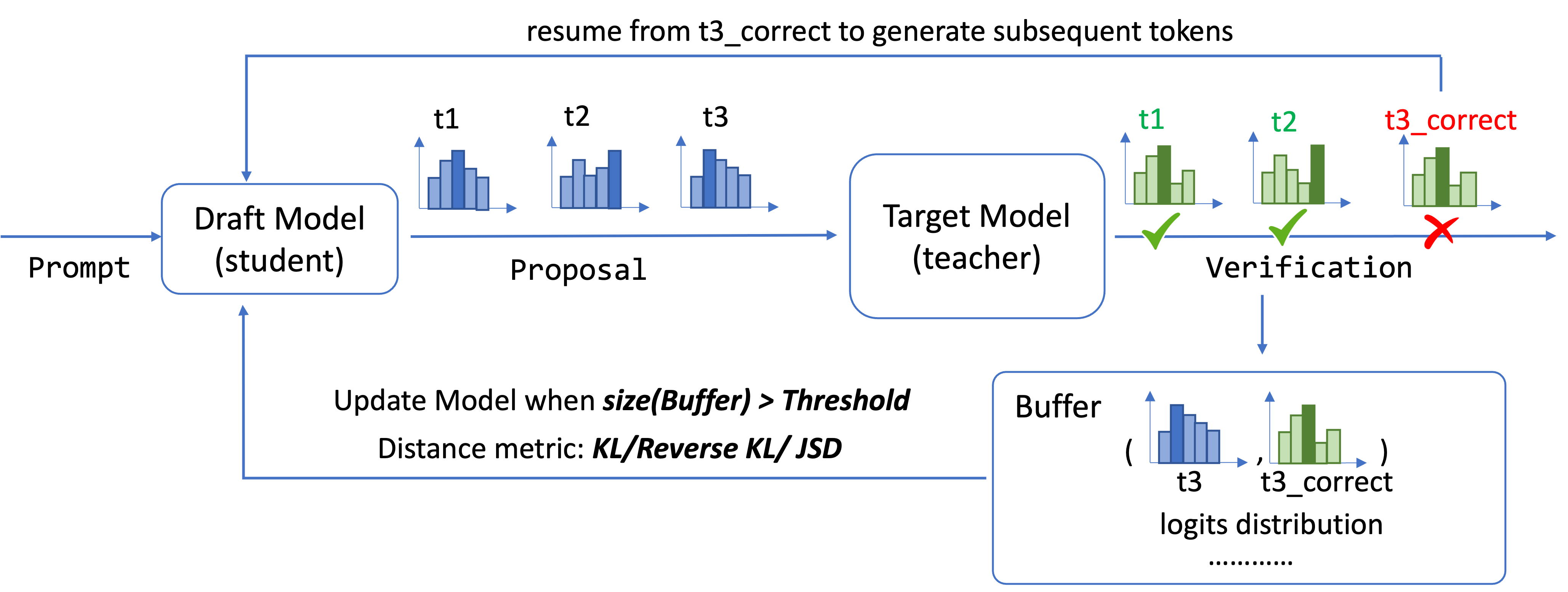
Online Speculative DecodingXiaoxuan Liu, Lanxiang Hu, Peter Bailis, Ion Stoica, Zhijie Deng, Alvin Cheung, Hao Zhang ICML, 2024 arxiv / code / We introduce online speculative decoding algorithm (OSD) with improved responsiveness, speculation accuracy and compatibility with LLM serving systems. |
Academic ServicesConference reviewer: ICML, ICLR, NeurIPS, COLM, ACL, ECCV. |
|
© 2024 Lanxiang Hu. Design and source code from Jon Barron's website, powered by Jekyll. |